In this article I will cover the installation of Exchange 2007 SP1 on Windows Server 2008. I will lay out which versions of Exchange are supported on which OS version and also which domain controller version they can use. I will detail the supported methods to move from Exchange 2007 on Window Server 2003, to Exchange 2007 on Windows Server 2008 and finally I will cover the prerequisites needed, before showing the actual install.
Note:
At this time, neither Windows Server 2008 nor Exchange Server 2007 SP1 have released to manufacturing. As I am therefore working with beta code, certain elements of what follows (in particular the screenshots, may change before the final version.
Introduction
It is nearly a year after the release of Exchange 2007 and many of us now have complete Exchange 2007 implementations. I guess that means we are looking for something new to do! If this is the case then you won’t be disappointed, as very soon we will be presented with the new challenge of moving our existing Exchange 2007 systems onto Windows Server 2008.
Table 1 lists the various supported scenarios for Exchange and OS versions.

Table 1: Exchange/OS versions supported for install
The first thing to note is that Exchange 2007 RTM is not supported on Windows Server 2008. To install Exchange 2007 on Server 2008 you must run Exchange 2007 SP1. This service pack, as many of you may know, is a little different from previous service packs in that it is a complete installation of Exchange. Effectively SP1 is RTM with the SP1 code slipstreamed into it. Having established that Exchange 2007 SP1 is required to install on Server 2008, what other considerations are there?
Probably the biggest consideration is Active Directory. Table 2 sets out the different Domain Controller versions supported by different versions of Exchange.
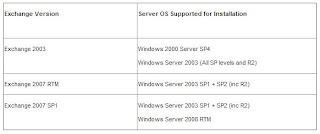
Table 2: The Exchange/Domain Controller support matrix
One new Active Directory feature of Windows Server 2008 which I haven’t mentioned is Read Only Domain Controllers (RODC) (and Global Catalog servers). These are servers which do not hold a writable copy of the AD and also do not hold account passwords. They are most likely to be used in branch office scenarios to prevent security breaches either intentional or accidental. So how do these RODCs affect Exchange? Simply put, Exchange doesn’t use them! When left to automatically associate with a domain controller (or global catalog server) Exchange will ignore the RODC or ROGC. The important thing for administrators to remember is not to manually set Exchange to work with a RODC as things simply will not work correctly.
One other area that will be welcome to administrators is that with the release of Exchange 2007 SP1, the Exchange Management Console will finally be supported on Windows Vista, and for that matter on Server 2008 as well.
Before moving on to how we upgrade, I think it is worth clarifying that Exchange 2007 SP1 will not install on Windows Server 2008 Server Core. Server Core, for those who haven’t heard, is a cut down version of Windows Server 2008 which only presents a command line interface. It has been stripped down to run various server roles including amongst others Domain Controller, DHCP, DNS, File and Print. However, because a lot of functionality has been stripped out to ensure a small footprint and less need for patching, important components such as the .Net Framework are not present to support Exchange.
Note:
As I mentioned we are currently working with beta code. It is because of this that the Unified Messaging role does not currently install on Server 2008. This will be rectified before release.
The upgrade path
So how do you actually get from Exchange 2007 running on Windows Server 2003 to Exchange 2007 SP1 running on Windows Server 2008?
Unfortunately, although understandably given the massive architecture changes involved, you cannot simply upgrade Exchange 2007 to Exchange 2007 SP1 and then upgrade the OS to Windows Server 2008. This simply breaks Exchange completely!
Even when you have a clustered mailbox server, you cannot perform a rolling upgrade by upgrading one node of the cluster failing over and then doing the other node.
The only way is to perform a migration! In other words you must do a clean install of Windows Server 2008 on a new server and then migrate your data. Mailboxes can be moved using the Move-Mailbox cmdlet and public folder data must be replicated.
This has caused a fair amount of discontent on various online forums but it is the only way!
Installation
Having looked at all the background, let’s get started with the installation. The first thing to cover is preparing your Windows Server 2008 machine for Exchange 2007. There are a bunch of prerequisites which must be met as listed below:
.Net Framework v2.0 or 3.0
PowerShell RTM
MMC 3.0 (installed by default)
IIS 7 (Various components needed by different roles)
For a much more detailed look at the requirements for each Exchange server role see Exchange 2007 System Requirements.
For now we are going to install an Exchange 2007 SP1 server in a new domain and new organisation. We will install the CAS, HT and Mailbox roles. In order to install the prerequisites we will run the following commands one after the other at a command prompt:
ServerManagerCmd -i RSAT-ADDS
ServerManagerCmd -i PowerShell
ServerManagerCmd -i Web-Server
ServerManagerCmd -i Web-ISAPI-Ext
ServerManagerCmd -i Web-Metabase
ServerManagerCmd -i Web-Lgcy-Mgmt-Console
ServerManagerCmd -i Web-Basic-Auth
ServerManagerCmd -i Web-Digest-Auth
ServerManagerCmd -i Web-Windows-Auth
ServerManagerCmd -i Web-Dyn-Compression
After the first command (RSAT-ADDS) you will need to reboot as shown in Figure 1.
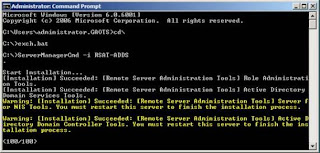
Figure 1: Installing Active Directory Management Tools and being prompted to reboot
After the reboot, I used a simple batch file to run the other commands in sequence. Part of the output from the commands is shown in Figure 2.
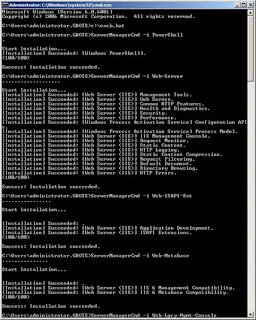
Figure 2: Part of the output from the prerequisite installation
For more detailed information about the Windows Server 2008 roles/features required for the other Exchange 2007 roles (Edge Transport Server and Unified Messaging Server) see How to Install Exchange 2007 SP1 Prerequisites on Windows Server 2008.
Having successfully completed the installation of prerequisites, it is time to install Exchange. Start setup and click “Install Microsoft Exchange Server 2007 SP1” as shown in Figure 3.
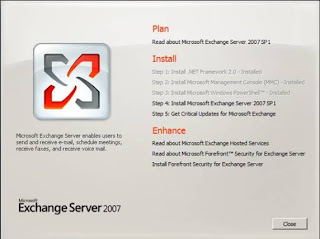
Figure 3: Starting Setup of Exchange Server 2007 SP1
Next run through the usual setup steps as shown in Figures 4 – 11.
Figure 4: The SP1 Setup introduction screen
Figure 5: Accepting the license agreement
Figure 6: Opting into the Microsoft Error Reporting scheme
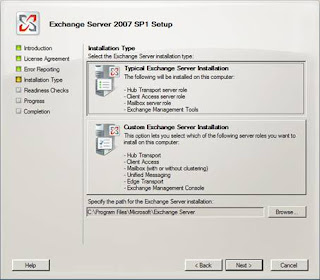
Figure 7: Selecting a typical install which installs CAS, HT, Mailbox roles and the management tools
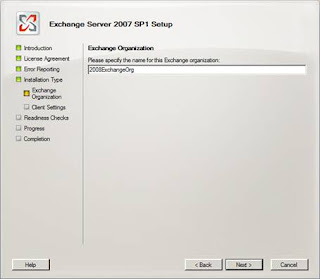
Figure 8: Setting the new Exchange Organisation name
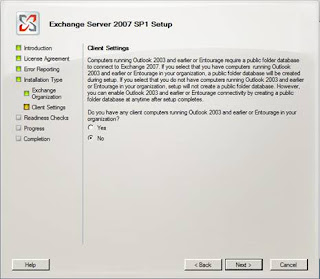
Figure 9: Opting not to create public folders for legacy clients

Figure 10: Exchange Readiness checks in progress

Figure 11: The not for production use warning before install about using a 32 bit version of Exchange 2007
Having completed the steps in Figures 3-11 installation begins. However, it is at this point that an error occurs as shown in Figure 12. It would appear that for whatever reason, the registry key “HKLM\SOFTWARE\Microsoft\Windows\Windows Error Reporting\Consent” does not exist!
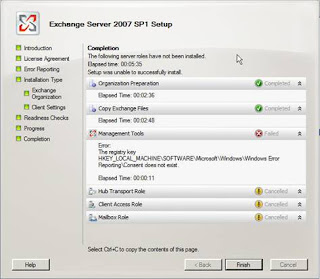
Figure 12: The registry key doesn’t exist error message
Note:
It is highly unlikely that this problem will still exist once the products ship.
To rectify this problem locate the relevant area in the registry and create the required key as shown in Figure 13.
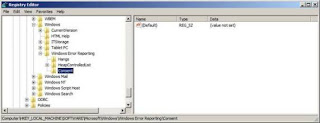
Figure 13: The newly created registry key
Having resolved the problem with the registry key you are left with no other option than to exit setup. On doing this you will be prompted to reboot, which you should do.
When the server is backed up, restart setup which will start in Exchange Maintenance Mode as shown in Figure 14.
Figure 14: Exchange setup restarting in Maintenance Mode
At this point, step through the remaining setup screens as shown in Figures 15-17.
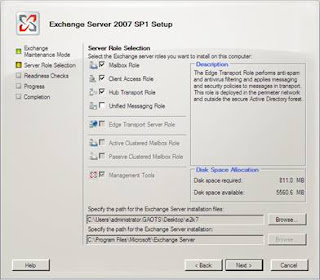
Figure 15: Selecting the relevant roles for installation
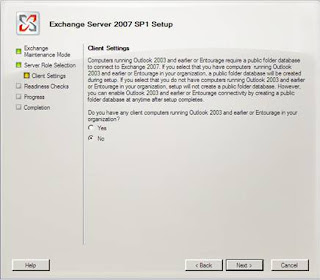
Figure 16: Again making the choice not to create public folders for legacy clients
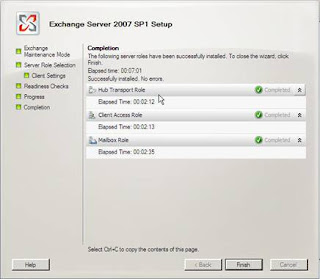
Figure 17: Setup completed!
Once setup completes you will have a working Exchange 2007 SP1 install on Windows Server 2008 as shown in Figure 18.
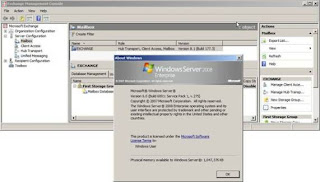
Figure 18: Exchange 2007 SP1 installed on Windows Server 2008
Before completing this article I thought it might be interesting to show the registry key that we created earlier. As can be seen in Figure 19, it is now populated with various values.
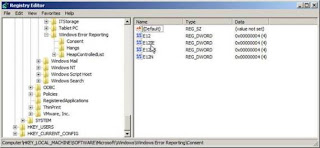
Figure 19: The values in the registry key created to solve the installation error
Summary
As you can see from the steps above, the install process to put Exchange 2007 on Windows Server 2008 is basically very simple. At this time there is the odd glitch but there is no doubt these will be ironed out before Release to Manufacturing. I feel the only thing that has the potential to cause a delay in deployment are the usual worries about deploying a brand new OS and the fact that if you already have Exchange 2007 on Server 2003 you will have to perform a migration which requires extra hardware.





































